
First App!
Day 2 on journey to create a distributed graph coding ai.
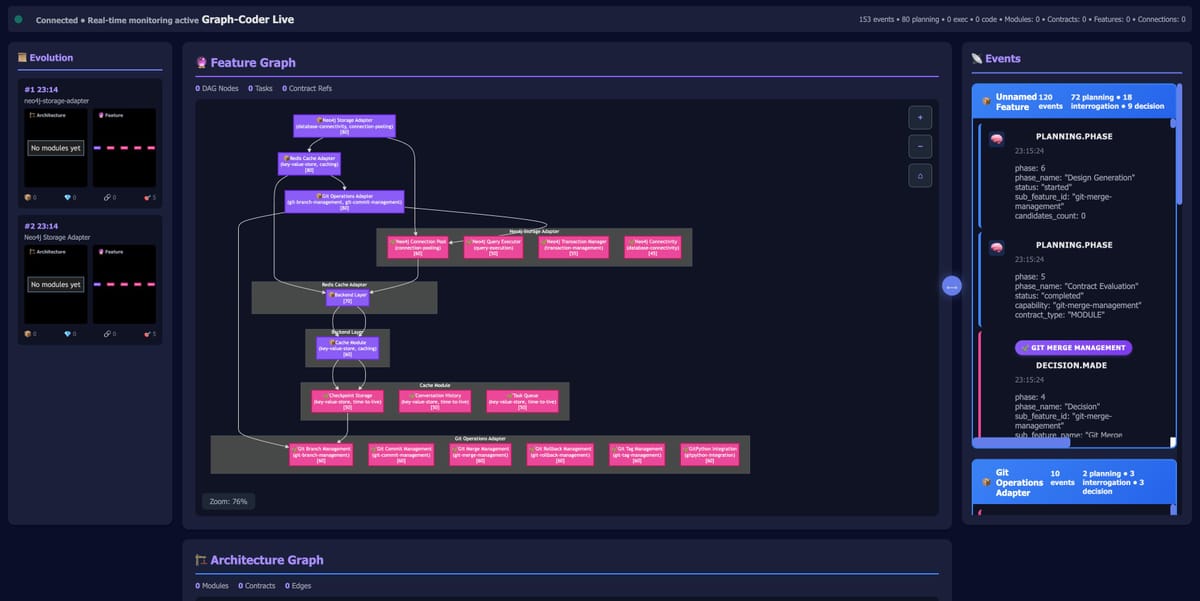
With my frustration with the poor capabilities of even the largest agents to deal with very large codebases, I started work on a distributed graph based coding copilot, working name for now: gcoder
Currently, even Claude Code & Cursor with Sonnet 4.5 [1M] fails to reliably debug large codebases - see my other blog posts on Heimdall architecture, and at a cost of $1 per minute - it gets extremely expensive.
My goal here is to create a coding ai, that can work on my projects at scale, very cheaply, accurately and very fast. The app below was generated in 30 sec, and cost $0, due to using local llm models.
Day 2 - first app created
Day 2, good progress, totally rewrote the entire codebase, and confirmed its capability by it generating and running its first working code.
Create a Flask web application that:
1. Has a form where users enter a name
2. Uses Anthropic Claude API to analyze the name's origin and meaning
3. Displays the AI-generated analysis
4. Includes error handling
Requirements
- Flask web framework
- Anthropic Python SDK
- HTML templates with Bootstrap styling
- Proper error handling and validation
- Docker containerization
- Environment variable configuration
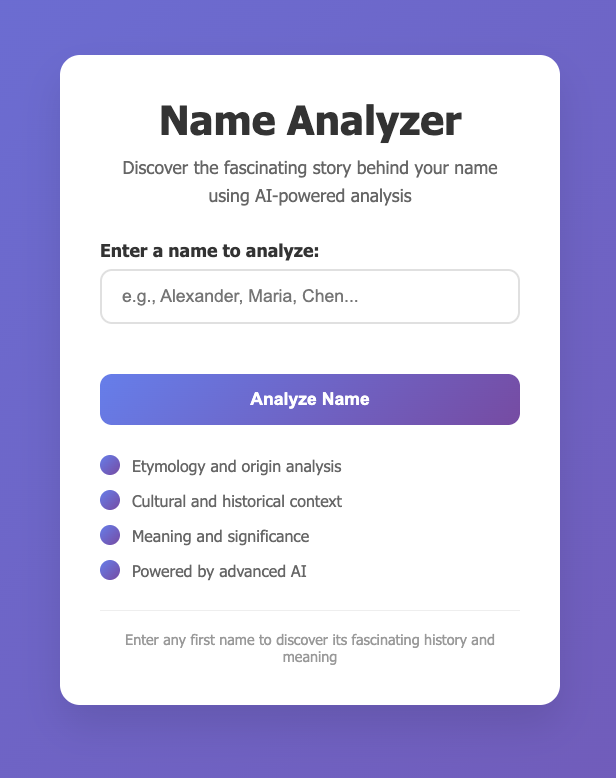
A small flask app that will look up the etymology of your name. This tests a few things:
- Ensuring all imports and requirements line up
- Debugging
- Importing secrets
- Being able to run the app in a local docker container
- Running tests against the app
- Debugging runtime errors

Overall, not bad for a single days work.. I think this proves the architecture is worth taking forward.
Technical Notes
Core Innovation
Traditional copilots treat code as text and dump entire repositories into LLM context windows. Heimdall instead:
- Represents everything as a graph - Code, domains, runtime, plans, security as interconnected nodes
- Uses graph queries first - Structure-based operations are instant and free
- Falls back to semantic search - Vector embeddings only when graph queries insufficient
- Reserves LLMs for reasoning - Planning, decisions, and generation only
The Three-Tier Intelligence Strategy
Tier 1: Graph Operations (70% of requests)
├─ OpenCypher queries on FalkorDB
├─ Pattern matching, traversals, graph algorithms
├─ Cost: $0, Latency: 50-200ms
└─ Use: Structure-based queries
Tier 2: Vector DB Embeddings (20% of requests)
├─ BERT embeddings via local encoder
├─ Semantic search when graph insufficient
├─ Cost: $0 (self-hosted), Latency: 50-100ms
└─ Use: Natural language → code mapping, external log linking
Tier 3: LLM Reasoning (10% of requests)
├─ Local: Qwen 32B, DeepSeek 33B, Llama 70B (80% of LLM work)
├─ API: Claude Haiku 4 (15% of LLM work)
├─ API: Claude Sonnet 4.5 (5% of LLM work - complex planning only)
├─ Cost: $0-$0.40/request, Latency: 1-5s
└─ Use: Planning, architectural decisions, code generation
Success Metrics
vs Traditional Copilots:
- 91% cost reduction ($1,900/mo vs $73,000/mo at 1K req/day)
- 4x faster (5s avg vs 20s+)
- 10x more accurate (graph-based precision vs text-based guessing)
- Infinite scale (no context window limits)
Targets:
- Code generation success: >80%
- Bug localization accuracy: >60% (top-5)
- Plan accuracy: >85%
- Latency P95: <7s
I'm making a significant number of additions today, including quite a few around contract negotiation - in this graph coder, contracts are all external dependencies: api's, configs, requirements, secrets, db tables/fields/orm, etc.
Any changes to an interface gets negotiated through the graph planner, between all the parties involved in an event driven manner.
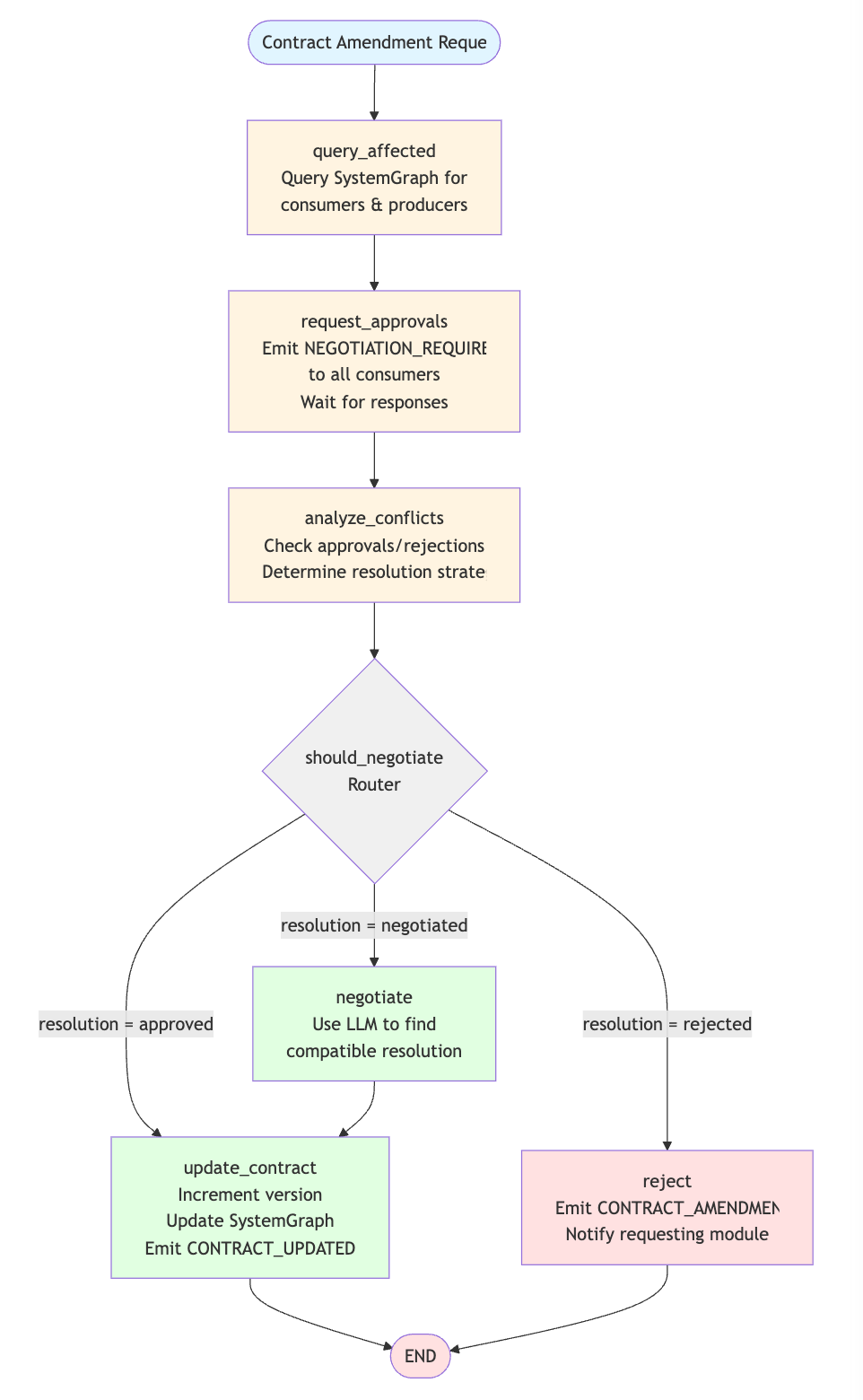
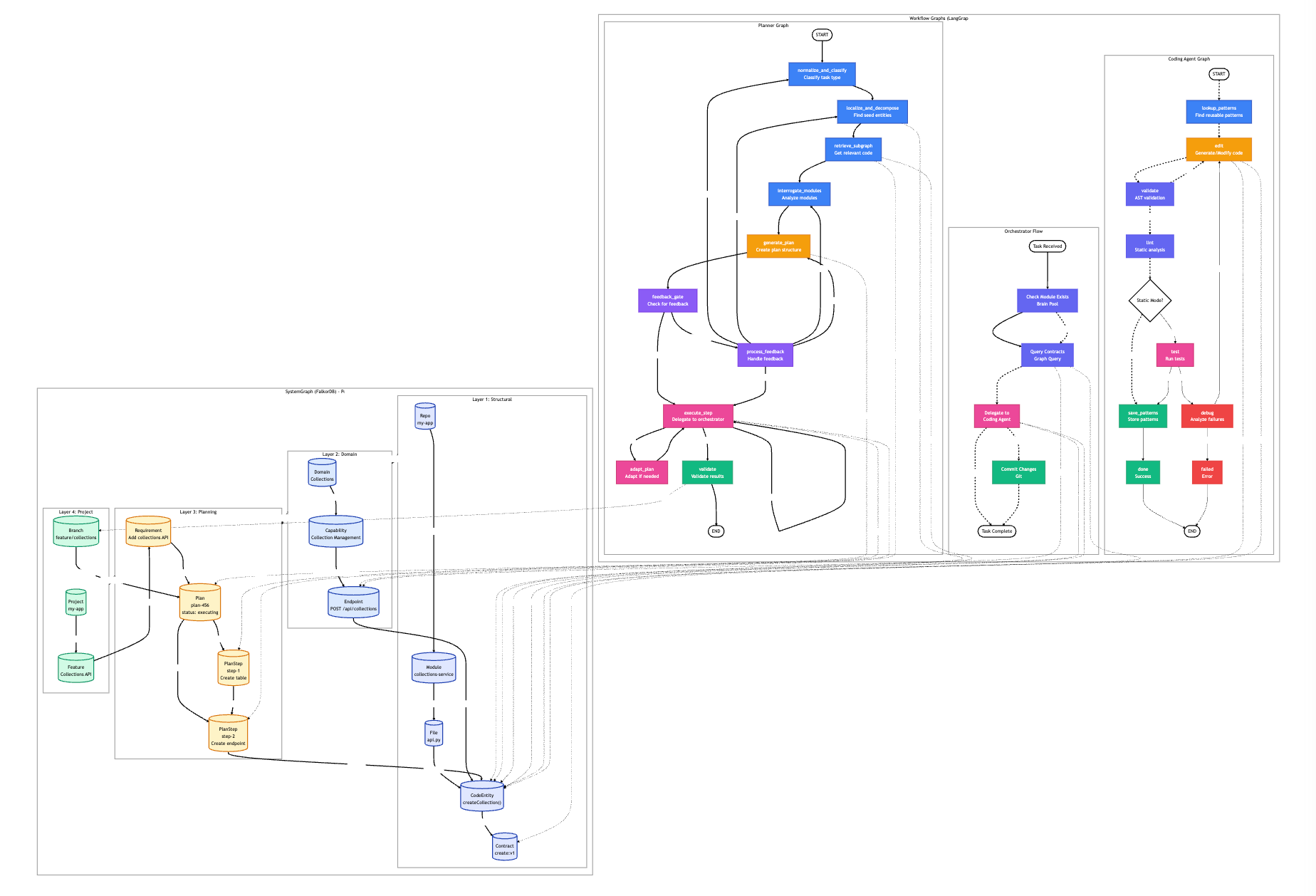
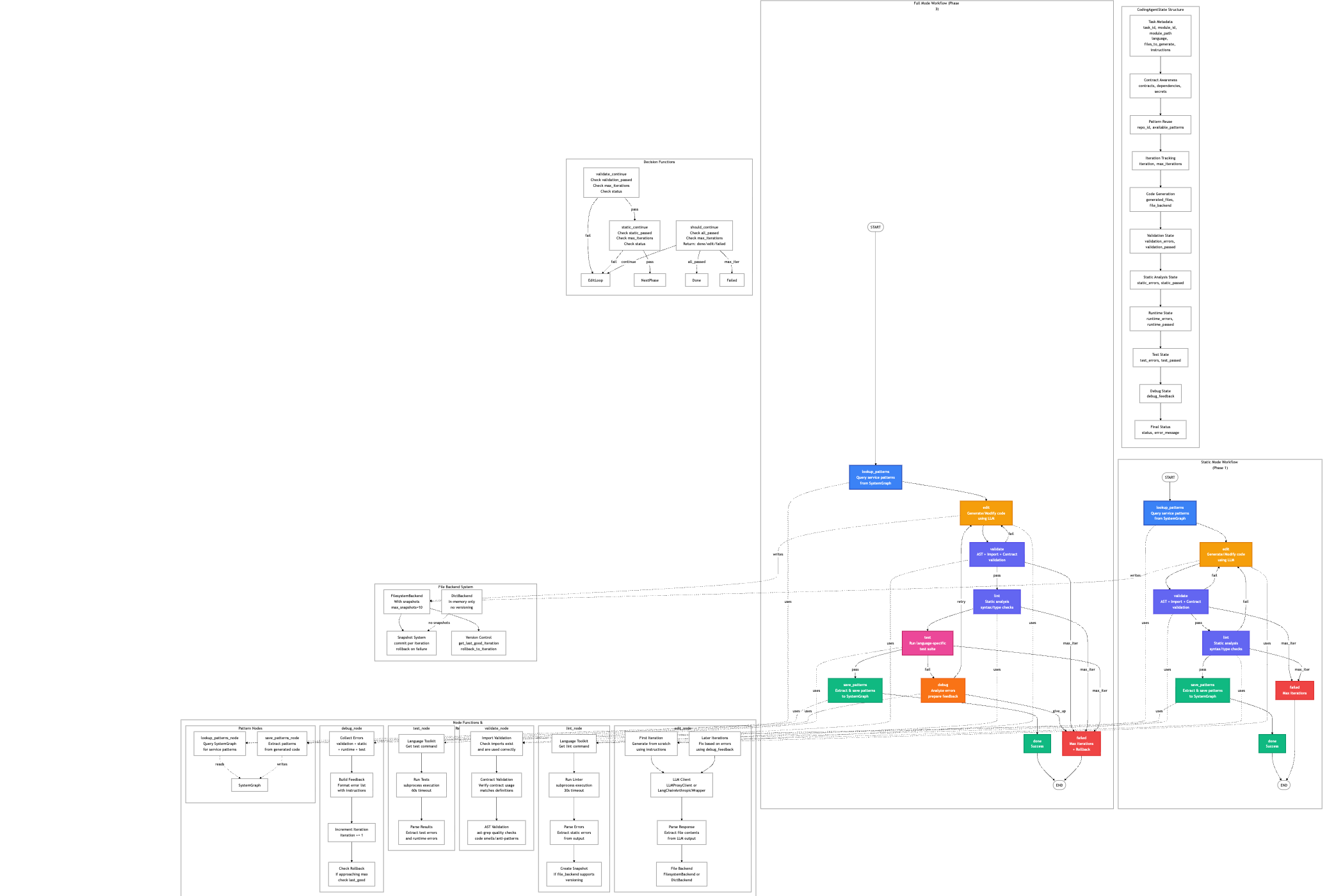
This is all very early days, so I expect I'll make significant changes to the whole system as I learn more.
See you next post